Layered MAPF Outperforms Raw Methods in Time and Memory Benchmarks
19 Feb 2026
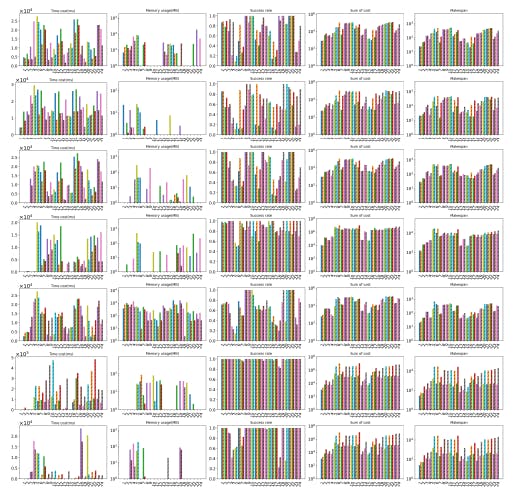
Layered MAPF reduces time and memory costs in large multi-agent pathfinding problems, improving success rates for serial solvers.
Why Layered MAPF Algorithms Win on Speed but Lose on Optimality
19 Feb 2026
Layered MAPF solvers cut runtime and memory use while boosting success rates—though often at the cost of longer paths and higher makespan.

Study Finds MAPF Decomposition Efficient Under Low Agent Density
19 Feb 2026
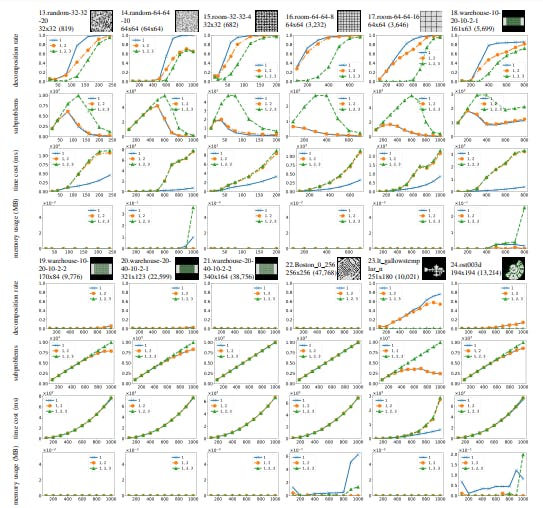
MAPF decomposition reduces solving time and memory—especially on sparse grids—but loses effectiveness as agent density increases.

A New Method for Decomposing MAPF Problems Into Solvable Subproblems
19 Feb 2026
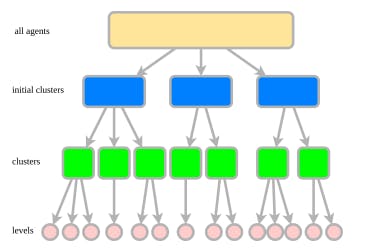
A structured method for decomposing MAPF into clusters and levels, enabling scalable, conflict-free solutions without sacrificing solvability.

A Smarter Way to Scale Multi-Agent Pathfinding
18 Feb 2026
A new LayeredMAPF framework decomposes multi-agent pathfinding into smaller subproblems, reducing complexity while preserving solvability.

Researchers Compare CBS, LNS, PBS, and PIBT in the Race to Speed Up Multi-Agent Pathfinding
18 Feb 2026
Survey of MAPF algorithms—from CBS and LNS to PBS and LaCAM—focused on reducing runtime while balancing optimality and scalability.
This New Decomposition Framework Makes Multi-Agent Pathfinding More Scalable
18 Feb 2026
A new decomposition framework reduces time and memory costs in multi-agent pathfinding without sacrificing solvability.

Beyond TPC-H: Scaling IA2 for Real-World Database Optimization
10 Jan 2026
IA2 sets a new standard for database optimization using the TD3-TD-SWAR model, offering superior efficiency and unseen workload generalization.

Adaptive Action Pruning: Scaling Index Selection for Unseen Workloads
10 Jan 2026
IA2 revolutionizes index selection with rapid training, reducing SQL runtime by 61% via adaptive action pruning and workload modeling