
Table of Links
-
RQ 1: Leveraging the Neighbourhood at Inference
5. RQ 2: Leveraging the Neighbourhood at Training
We leverage the knowledge from neighbour instances directly at the training process to improve the performance. We explore three methods: contrastive learning, single prototypical learning, and multi prototypical learning. These techniques draw inspiration from the same principles as their inference-time counterparts but serve as auxiliary loss constraints during training. Their primary aim is to improve the discriminative capability of embeddings by highlighting differences between instances with distinct rhetorical roles and similarities among instances sharing the same label.
While the task-specific classification loss focuses on mapping contextualized representations to label outputs with supervision on individual instances, the methods in this section directly operate on embeddings in latent space. They exploit the interplay among instances to establish effective discriminative decision boundaries, serving as a form of regularization.
5.1. Methods
5.1.1. Contrastive Learning
Contrastive learning aims to bring an anchor point closer to related samples while pushing it away from unrelated samples in the embedding space. In a supervised setting, samples with the same/different labels are considered related/unrelated with respect to an anchor (Khosla et al., 2020). The loss is calculated as follows:
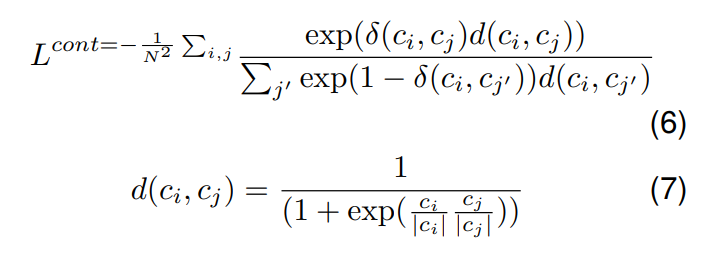
where δ(ci , cj ) denotes 1 if ci and cj have same rhetorical label, else 0, N denotes batch size.
Lengthy legal documents limits the number of documents that can be accommodated in a single batch and this raises concerns about having enough positive samples for the minority class instances within a batch for effective contrasting. To overcome this limitation, we utilize a memory bank (Wu et al., 2018), where we progressively reuse encoded representations from previous batches to compute the contrastive loss. In practice, we maintain a fixed-size representation queue for each rhetorical role. As new representations corresponding to specific labels are generated, they are enqueued into the respective queue with their gradients detached. If the queue size for a label exceeds the maximum limit, the oldest element is dequeued. When computing the contrastive loss, we use the same equation 7. However, in addition to the current batch instances, we employ all the representations stored in the memory bank for contrasting purposes, using them as both positives and negatives, based on the anchor point’s label.
To incorporate the concept of context from surrounding sentences into contrastive learning, we introduce a novel discourse-aware contrastive loss. This is based on the idea that sentences in close proximity within a document, sharing the same label, should exhibit a stronger proximity in the embedding space compared to sentences with the same label but positioned farther apart in the document. To implement this concept, we introduce a penalty inversely proportional to the absolute difference in their positions. In particular, we impose a higher penalty on positive sentence pairs that are closer in the document, encouraging them to be closer in the embedding space than pairs originating from greater distances within the document. The discouse-aware loss is as follows:
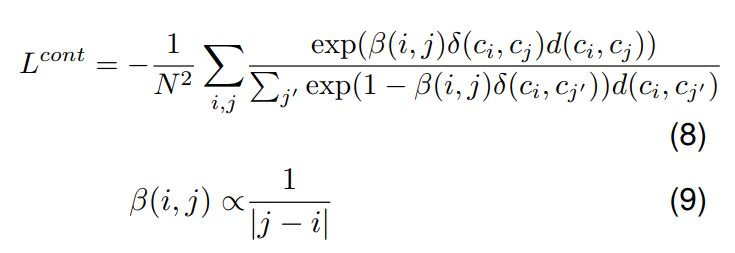
where β represents a penalty that considers positional information. When ci and cj come from different documents, such as cross-document positives/negatives from the memory bank or across the batch, we apply the lowest possible penalty, considering ci as the farthest sentence relative to in-document positives. We incorporate this additional contrastive loss alongside the classification loss during training.
5.1.2. Single Prototypical Learning

These both views shape the embedding space by aligning prototypes with their corresponding samples, forming distinct clusters of different labels, each centered around a specific prototype vector.
5.1.3. Multi Prototypical Learning
Instead of using a single prototype for each label, this approach employs multiple prototypes for each label to capture the diverse variations within the sentences of the same label. To implement this, a set of M prototypes per label is randomly initialized and a diversity loss (Zhang et al., 2022) is integrated to penalize prototypes of the same label if they are too similar to each other. This ensures that prototypes of the same label are distributed across the embedding space, capturing the multifaceted nuances under each label. The Sample Centric View is also modified to ensure that each sample is in close proximity to at least one prototype among all the prototypes of the same class.

Authors:
(1) Santosh T.Y.S.S, School of Computation, Information, and Technology; Technical University of Munich, Germany ([email protected]);
(2) Hassan Sarwat, School of Computation, Information, and Technology; Technical University of Munich, Germany ([email protected]);
(3) Ahmed Abdou, School of Computation, Information, and Technology; Technical University of Munich, Germany ([email protected]);
(4) Matthias Grabmair, School of Computation, Information, and Technology; Technical University of Munich, Germany ([email protected]).
This paper is