Table of Links
-
RQ 1: Leveraging the Neighbourhood at Inference
5.2. Experiments
5.2.1. Implementation Details
We use the same training setup as described in Sec. 4.2.1. We conduct grid-search for size of memory bank per label and number of prototypes in multi-prototypical learning in powers of 2 from [32,512] and [4,256] respectively using the validation set performance.
5.2.2. Results
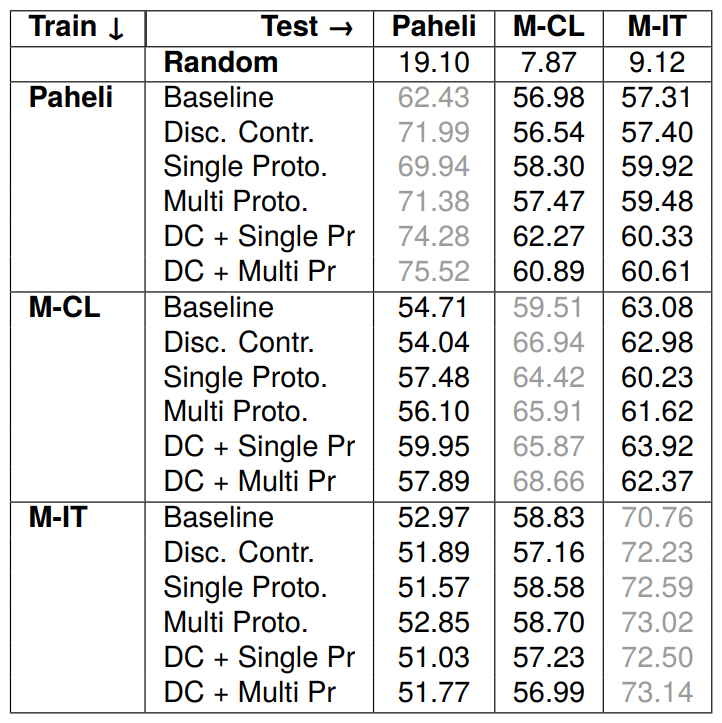
Table 2, shows that incorporating contrastive loss improves performance across all datasets. Furthermore, the discourse-aware contrastive loss, which leverages relative position to organize embeddings,
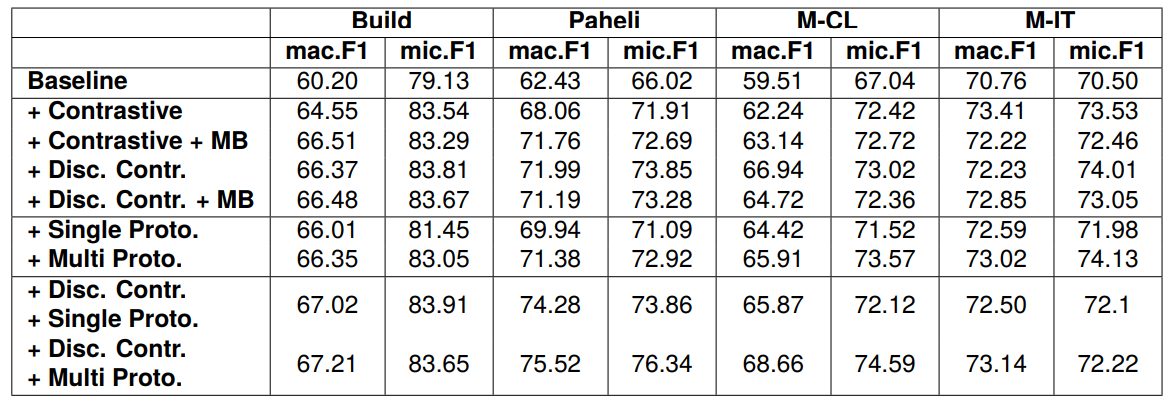
enhances performance, supporting our hypothesis that sentences with the same label and in close proximity in the document should be closer in the embedding space. Augmenting the contrastive loss with a memory bank further enhances performance, particularly in macro-F1, benefiting sparse classes. However, the degree of improvement is less or negative in the discourse-aware variant. This can be due to the positional factor, as additional sentences from other documents retrieved from the memory bank are placed at the end of the document, leading to smaller penalization factors and contributing only marginally to the loss. Overall, the discourse-aware contrastive model emerges as the most effective among the contrastive variants.
The single prototypical variant performs comparably to the best contrastive variant and outperforms the baseline. This demonstrates that specific guiding points through prototypes can effectively aggregate knowledge from neighboring instances. Moreover, multiple prototypes further improve performance, highlighting the need to capture multifaceted nuances. These results suggest that the addition of respective losses can eliminate the need to design specific memory banks to expose the model to large batches for effective guidance from neighbors in contrastive learning.
Finally, combining the discourse-aware contrastive variant with both single and multiple prototype variants yields further improvement, highlighting the complementarity between these approaches. These results suggest that deriving supervisory signals from interactions among training instances can be an effective strategy for addressing the class imbalance problem, particularly in low-data settings.
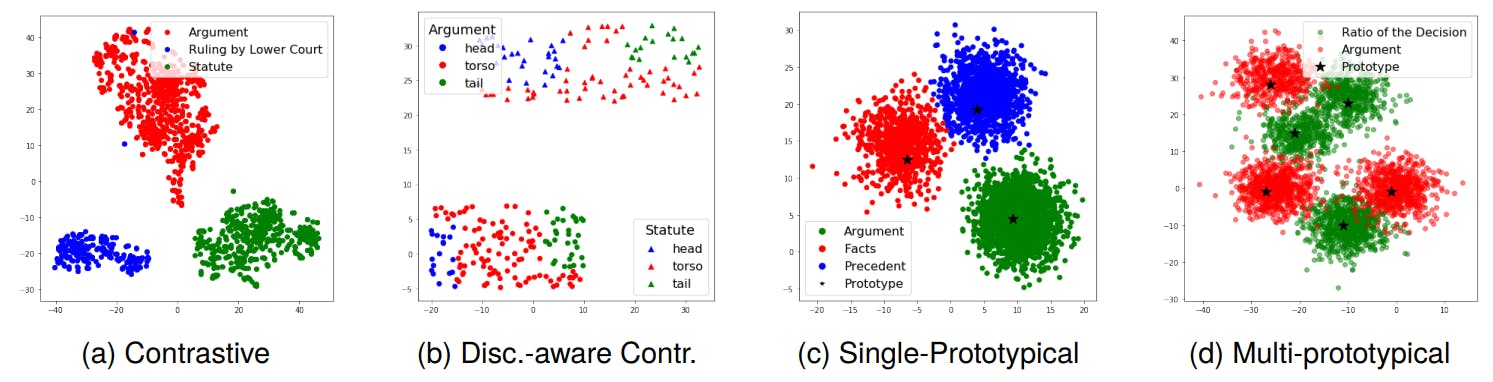
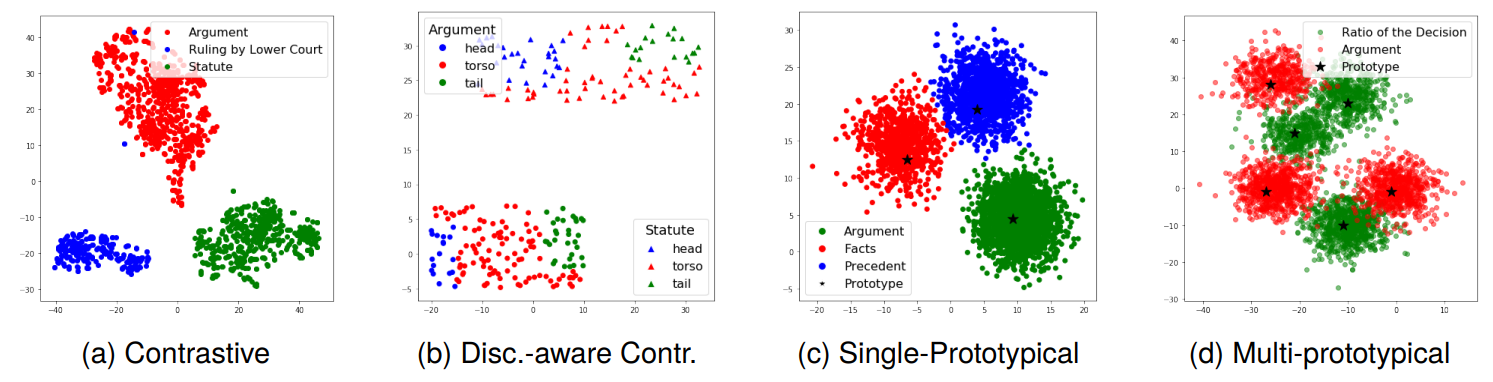
Qualitative Analysis: To examine the impact of our auxiliary loss functions on the learned representations, we employ t-SNE (Hinton and Roweis, 2002) to project the high-dimensional latent space hidden states obtained by the model in Fig. 2. In the case of contrastive learning, we observe that sentences with the same label form distinct clusters. With the addition of discourse-aware contrastive loss, samples with the same label in a specific document adhere to the positional constraint, aligning with our hypothesis that samples sharing a label and closer in the discourse sequence should be positioned closer in the embedding space compared to those farther apart. In single prototypical learning, prototypes occupy the centers of corresponding sentences, forming distinctive manifolds. Similarly, multi-prototypical learning captures multifaceted aspects with prototypes dispersed across the embedding space, each prototype serving as
the center for respective samples. These visualizations affirm the effectiveness of our learning methods.
Authors:
(1) Santosh T.Y.S.S, School of Computation, Information, and Technology; Technical University of Munich, Germany ([email protected]);
(2) Hassan Sarwat, School of Computation, Information, and Technology; Technical University of Munich, Germany ([email protected]);
(3) Ahmed Abdou, School of Computation, Information, and Technology; Technical University of Munich, Germany ([email protected]);
(4) Matthias Grabmair, School of Computation, Information, and Technology; Technical University of Munich, Germany ([email protected]).
This paper is