Table of Links
-
Method
-
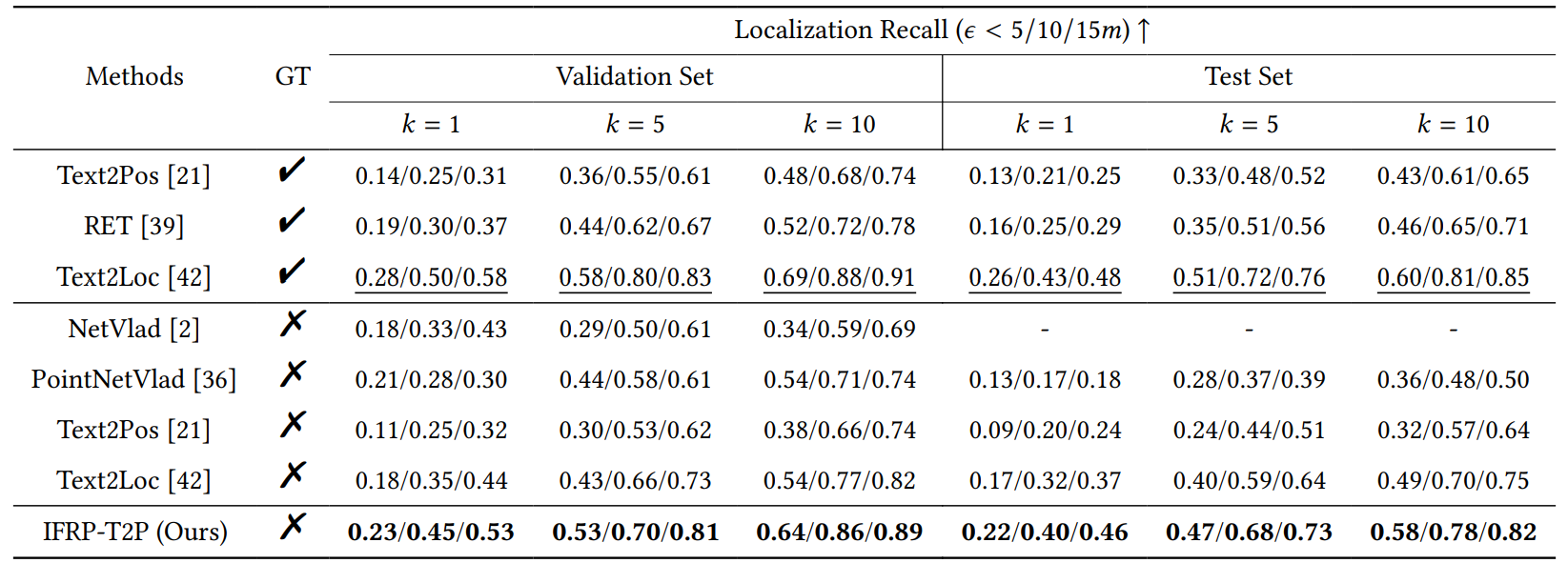
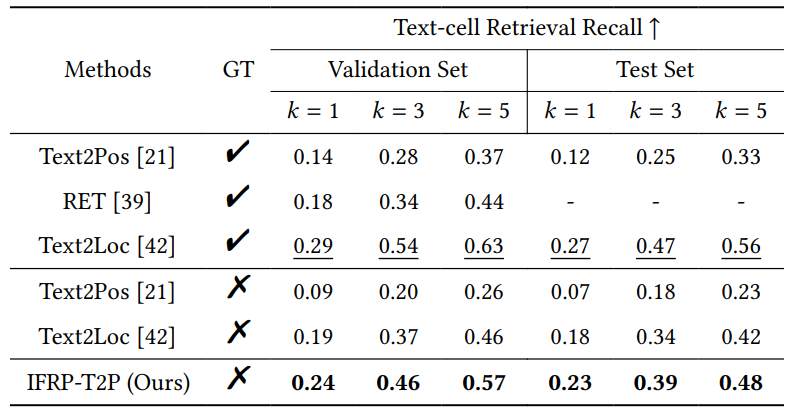
Experiments
-
Performance Analysis
Supplementary Material
- Details of KITTI360Pose Dataset
- More Experiments on the Instance Query Extractor
- Text-Cell Embedding Space Analysis
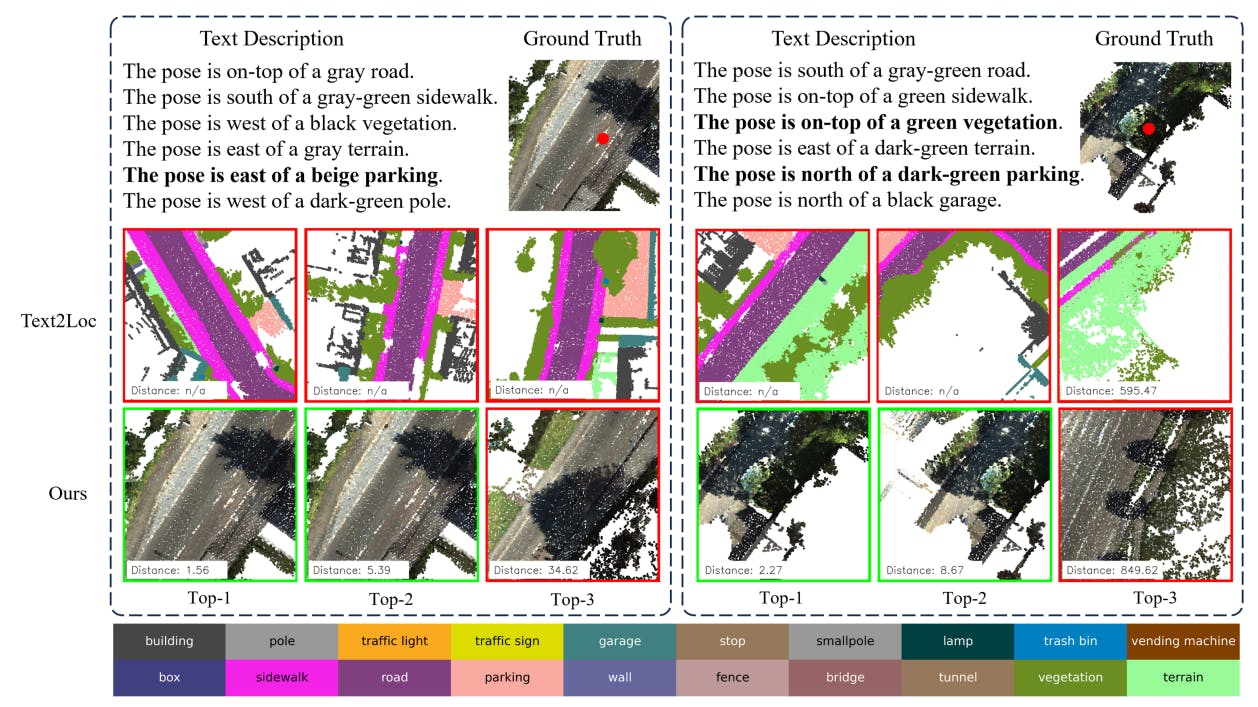
- More Visualization Results
- Point Cloud Robustness Analysis
Anonymous Authors
- Details of KITTI360Pose Dataset
- More Experiments on the Instance Query Extractor
- Text-Cell Embedding Space Analysis
- More Visualization Results
- Point Cloud Robustness Analysis
4 EXPERIMENTS
4.1 Dataset Description
We evaluate our IFRP-T2P model on the KITTI360Pose dataset [21]. This dataset encompasses 3D point cloud scenes from nine urban areas, spanning a city-scale space of 15.51 square kilometers and consisting of 43,381 paired descriptions and positions. We utilize five areas for our training set and one for validation. The remaining three areas are used for testing. Each 3D cell within this dataset is represented by a cube measuring 30 meters on each side, with a 10-meter stride between each cell. More details are provided in the supplementary material.
4.2 Implementation Details
Our approach begins with pre-training the instance query extractor. This is accomplished through the instance segmentation objective, as outlined in Section 3.2. Our feature backbone employs a sparse convolution U-Net, specifically a Minkowski Res16UNet34C [10] with 0.15 meter voxel size. To align with the requirements of the KITTI360Pose configuration, we utilize cell point clouds, each encompassing a 30 meter cubic space, as our input. The training extends over 300 epochs, utilizing the AdamW optimizer. In the coarse stage, we train the text-cell retrieval model with AdamW optimizer with a learning rate of 1e-3. The model is trained for a total of 24 epochs while the learning rate is decayed by 10 at the
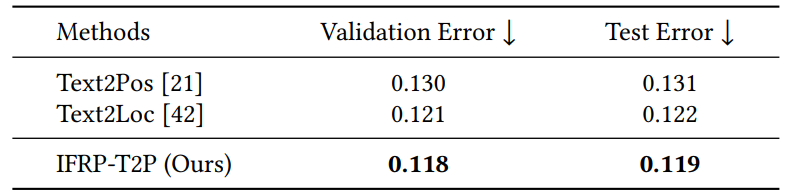
12-th epoch. In the fine stage, we train the regression model with Adam optimizer with a learning rate of 3e-4 for 12 epochs.
Authors:
(1) Lichao Wang, FNii, CUHKSZ ([email protected]);
(2) Zhihao Yuan, FNii and SSE, CUHKSZ ([email protected]);
(3) Jinke Ren, FNii and SSE, CUHKSZ ([email protected]);
(4) Shuguang Cui, SSE and FNii, CUHKSZ ([email protected]);
(5) Zhen Li, a Corresponding Author from SSE and FNii, CUHKSZ ([email protected]).
This paper is