
Table of Links
Supplementary Material
-
Image matting
-
Video matting
5.1. Pre-training on image data

Quantitative results. We evaluated our model against previous baselines after retraining them on our I-HIM50K dataset. Besides original works, we modified SparseMat’s
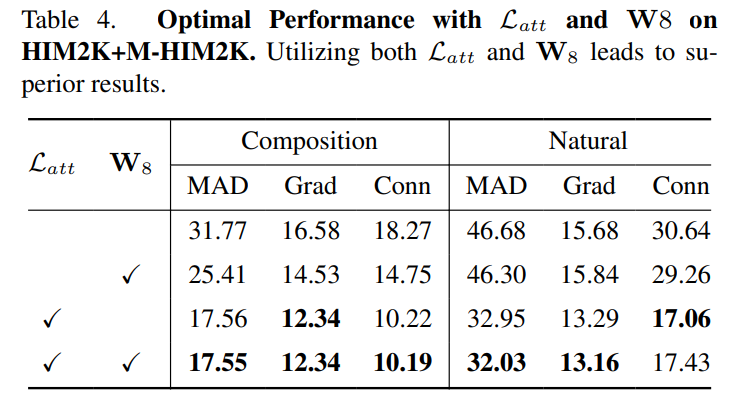
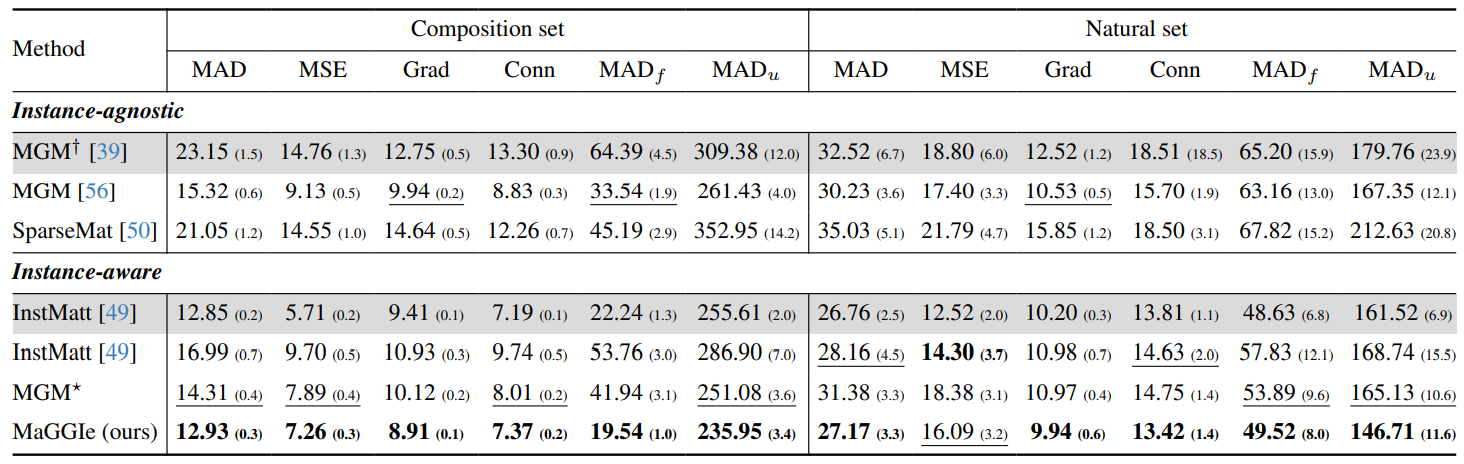
first layer to accept a single mask input. Additionally, we expanded MGM to handle up to 10 instances, denoted as MGM⋆ . We also include the public weights of InstMatt [49] and MGM-in-the-wild [39]. The performance with different masks M-HIM2K are reported in Table 5. The public InstMatt showed the best performance, but this comparison may not be entirely fair as it was trained on private external data. Our model demonstrated comparable results on composite and natural sets, achieving the lowest error in most metrics. MGM⋆ also performed well, suggesting that processing multiple masks simultaneously can facilitate instance interaction, although this approach slightly impacted the Grad metric, which reflects the output’s detail.
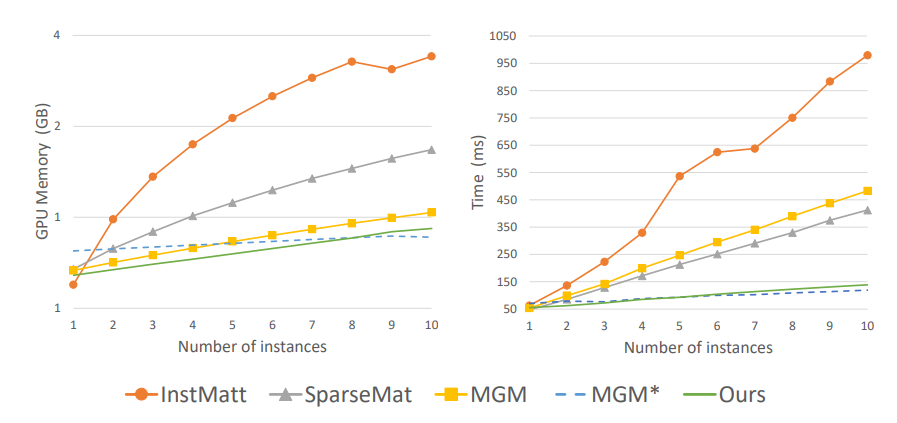
We also measure the memory and speed of models on M-HIM2K natural set in Fig. 4. While InstMatt, MGM, and SparseMat have the inference time increasing linearly to the number of instances, MGM⋆ and ours keep steady performance in both memory and speed.
Qualitative results. MaGGIe’s ability to capture fine details and effectively separate instances is showcased in Fig. 5. At the exact resolution, our model not only achieves highly detailed outcomes comparable to running MGM separately for each instance but also surpasses both
the public and retrained versions of InstMatt. A key strength of our approach is its proficiency in distinguishing between different instances. This is particularly evident when compared to MGM, where we observed overlapping instances, and MGM⋆ , which has noise issues caused by processing multiple masks simultaneously. Our model’s refined instance separation capabilities highlight its effectiveness in handling complex matting scenarios.
Authors:
(1) Chuong Huynh, University of Maryland, College Park ([email protected]);
(2) Seoung Wug Oh, Adobe Research (seoh,[email protected]);
(3) Abhinav Shrivastava, University of Maryland, College Park ([email protected]);
(4) Joon-Young Lee, Adobe Research ([email protected]).
This paper is